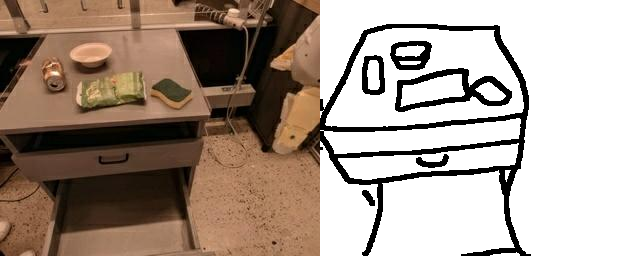
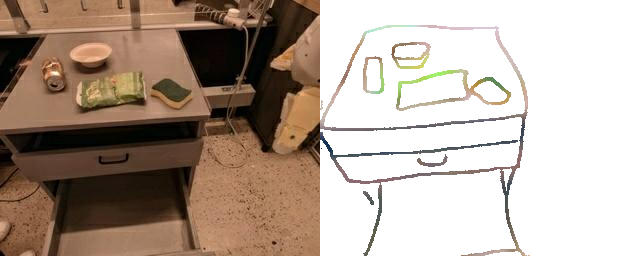
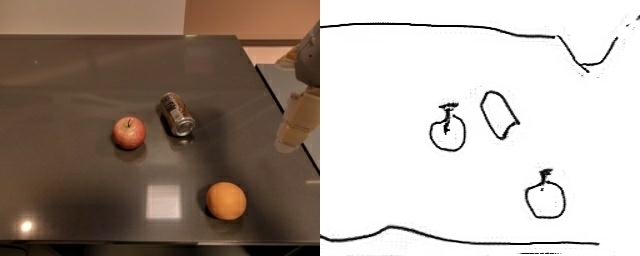
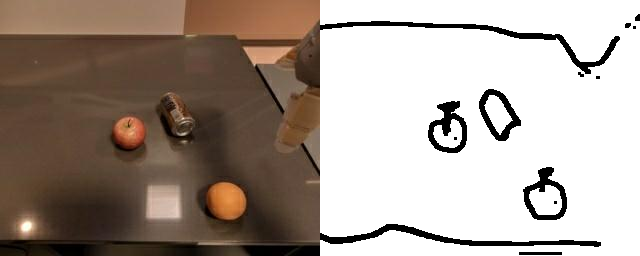
Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings.
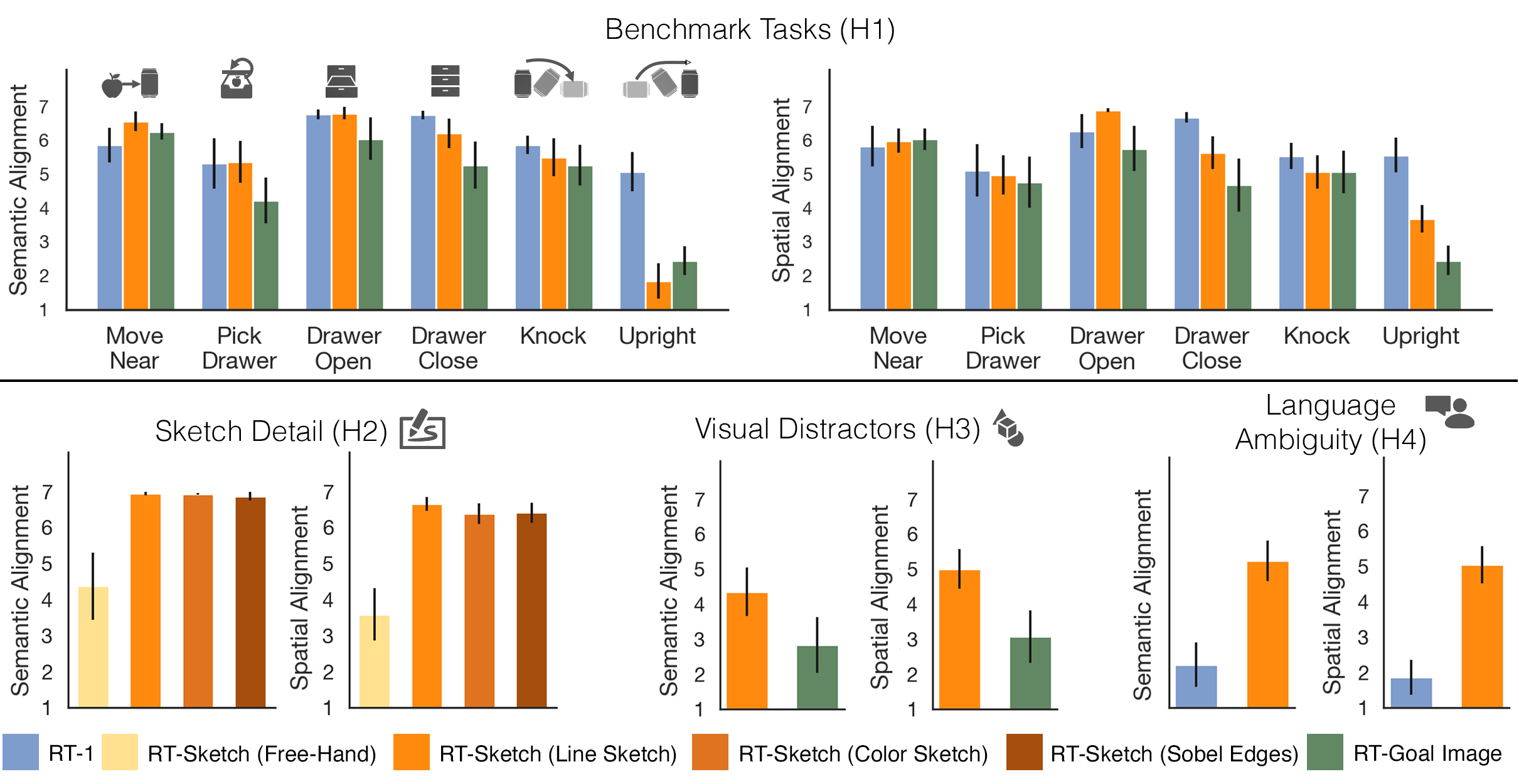
For straightforward manipulation tasks such as those in the RT-1 benchmark, RT-Sketch performs on par with language-conditioned and image-conditioned agents for nearly all skills:
RT-Sketch further affords input sketches with varied levels of detail, ranging from free-hand sketches to colorized sketches, without a performance drop compared to upper-bound representations like edge-detected images.
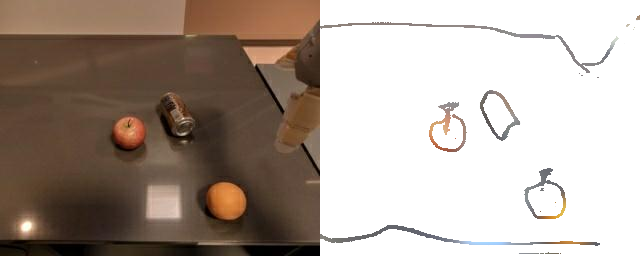
Although RT-Sketch is only trained on distractor-free settings, we find that it is able to handle visual distractors in the scene well, while goal-image conditioned policies are easily thrown out of distribution and fail to make task progress. This is likely due to the minimal nature of sketches, which inherently helps the policy attend to only task-relevant objects.
While convenient, language instructions can often be underspecified, ambiguous, or may require lengthy descriptions to communicate task goals effectively. These issues do not arise with sketches, which offer a minimal yet expressive means of conveying goals. We find that RT-Sketch is performant in scenarios where language can be ambiguous or too out-of-distribution for policies like RT-1 to handle.
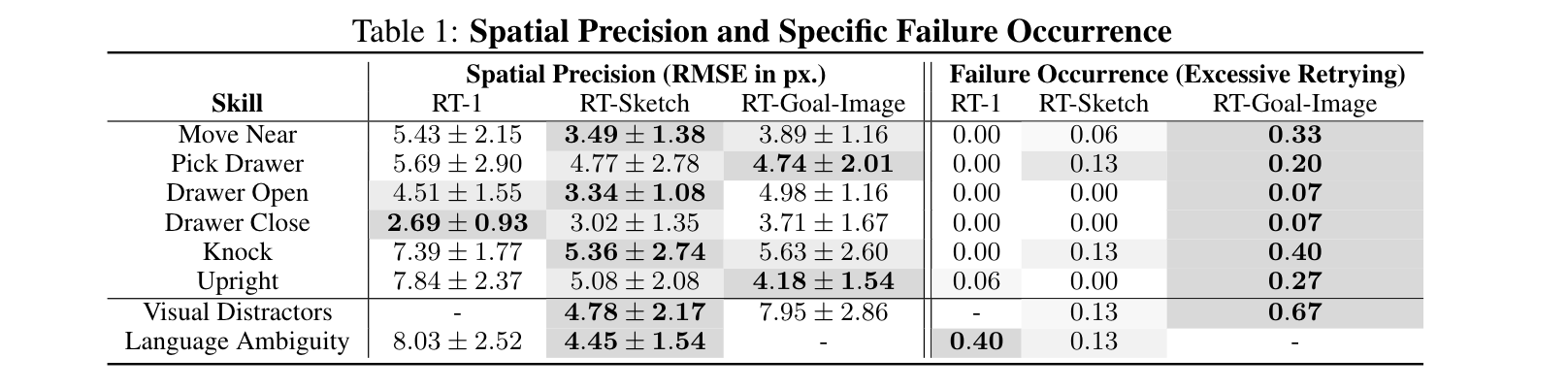
RT-Sketch's main failure modes are imprecision and moving the wrong object. We see the first failure mode typically when RT-Sketch positions an object correctly but fails to reorient it (common in the upright task). The second failure mode is most apparent in the case of visual distractor objects, where RT-Sketch mistakenly picks up the wrong object and puts in the appropriate place. We posit that both of these failures are due to RT-Sketch being trained on GAN-generated sketches, which occasionally do not preserve geometric details well, leading the policy to not pay close attention to objects or object orientations.
Coke can moved to correct location, but not upright
Pepsi can moved to correct location, but not upright
Apple moved instead of coke can
Coke can moved instead of fruit